Why cloning is a performance tuner's best friend
I’ve often been called into POCs to remediate poorly performing queries.
I remember one POC in particular, on a different platform to Snowflake, where the volume of data and the complexity of the pipeline was such that I could only perform 2-3 tests per day. It would take around one hour to execute the pipeline, but almost three hours to reset all the data for its next execution.
The test data set was tens of terabytes. The pipeline involved more than 60 large tables, many of which contained tens of billions of rows. The platform scale was capped by the customer, and there was insufficient capacity and time to recreate test databases using backup/restore. The fastest available solution was to drop and CTAS copies of the tables that were modified by the pipeline.
Snowflake solves that problem with zero-copy cloning databases, schemas or tables.
The most simple option is to clone the database. Cloning is a metadata-only operation that doesn’t duplicate the data, so it takes seconds to create the clone. It also means that you don’t pay for any additional storage until the data in the clone is modified, in which case only the changed micro-partitions are stored in the clone database.
Here’s an example.
-- Capture a baseline state of the database for repeatable testing. Data
-- can be modified in the original NYTAXI, but it won't change my baseline.
-- Metadata only, seconds to execute.
create or replace database nytaxi_baseline clone nytaxi;
-- Create a test clone from the baseline. This is how I get repeatability,
-- as I can modify the data in NYTAXI_TEST and simply replace it with
-- the baseline to reset for each run.
-- Metadata only, seconds to execute.
create or replace database nytaxi_test clone nytaxi_baseline;
-- Run pipeline/s in NYTAXI_TEST clone. I can re-clone NYTAXI_TEST
-- and re-run the test pipeline as many times as I need.
use nytaxi_test;
update public.trip set totalamount = 2.0 * totalamount;
-- Finished tests, clean up.
drop database nytaxi_test;
drop database nytaxi_baseline;
Side comment: How great is CREATE OR REPLACE? No more having to test for object existence, remembering the parameters for each object type, then conditionally dropping the object if it exists.
Here’s how long it took to run on my XS-size test platform.
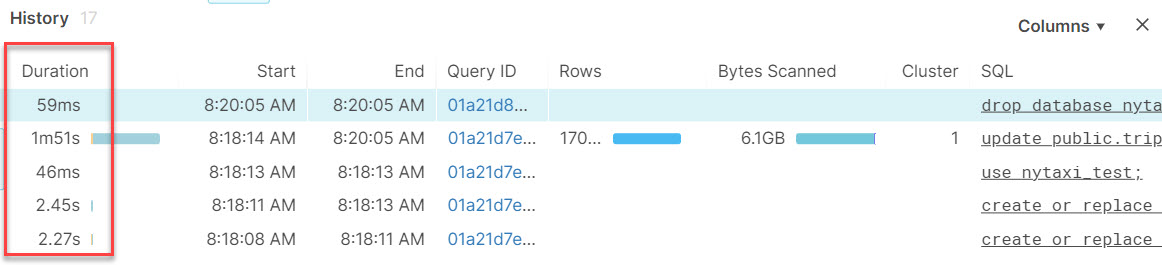
Testing like this has huge benefits over alternative approaches.
- Everything SQL, no messing around in portals or scripting languages.
- FAST. No more sitting around waiting for long-running restore or CTAS operations.
- Frugal. All it cost me was the time to run the test query, and some short-term storage of the rows modified by the test. In this case, a few cents.
And best of all, I could perform many times more iterations per day, delighting my customer with a fast performing query in a reasonable time.